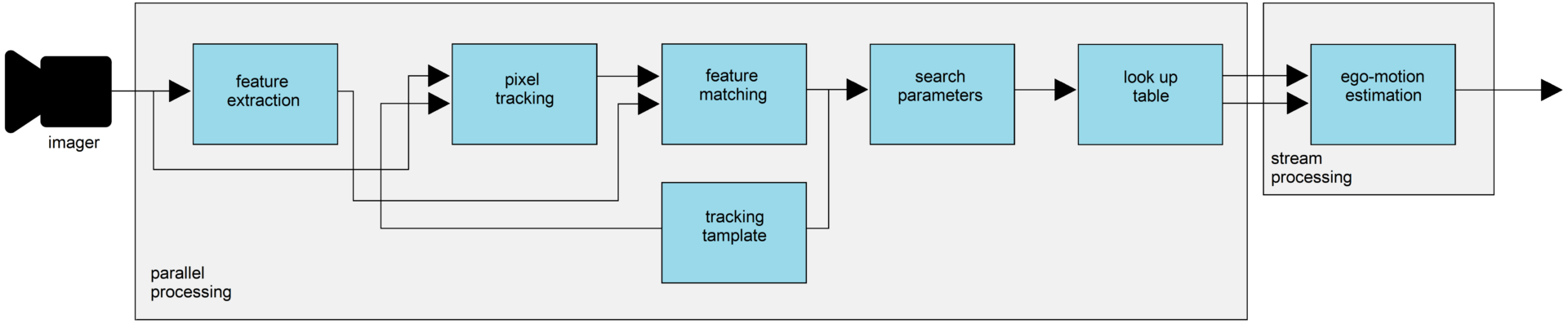
In this work, we propose a hardware architecture for “ego-motion challenge” that consists of using look-up tables and a new feature matching algorithm. Unlike previous work, camera motion is estimated with no iterative loop and no geometrical constraints. Experimental results demonstrated that a small medium size GPU-based implementation is feasible and suitable for embedded applications. It is possible to reach higher accuracy (95.07% of accuracy) compared with previous monocular VO algorithms algorithms such as CNN and depth learning-based approaches with a processing speed up to 17 times faster than previous works and suitable for embedded implementation.
The proposed GPU architecture
Results for the INAOE/DREAM benchmark dataset, sequence 48, 1280×720 image resolution.
For more details about this dataset, please see https://dream.ispr-ip.fr/ispr-benchmark-dataset/)
Results for the KITTI benchmark dataset, sequence 05, 1240×376 image resolution.
For more details about this dataset, please see http://www.cvlibs.net/datasets/kitti/eval_odometry.php